Treap
简介
Treap(树堆)是一种 弱平衡 的 二叉搜索树。
Treap 的结点除了被维护的 权值()之外,还附加了一个随机的 优先级()。其中,权值满足二叉搜索树性质,优先级满足堆性质(小根堆或大根堆)。
其中,二叉搜索树的性质是指:
- 左子节点的权值()比父节点小。
- 右子节点的权值()比父节点大。
堆的性质是:
- 子节点优先级()比父节点大或小(取决于是小根堆还是大根堆)。
不难看出,如果用的是同一个值,那么这两种数据结构在组合后会变成一条链,所以我们再在搜索树的基础上,引入一个给堆的值 。对于 值,我们维护搜索树的性质,对于 值,我们维护堆的性质。其中 这个值是随机给出的。
下图就是一个 Treap 的例子(这里使用的是小根堆,即根节点的优先级最小)。

那我们为什么需要大费周章的去让这个数据结构符合树和堆的性质,并且随机给出堆的值呢?
要理解这个,首先需要理解朴素二叉搜索树的问题。在给朴素搜索树插入一个新节点时,我们需要从这个搜索树的根节点开始递归,如果新节点比当前节点小,那就向左递归,反之亦然。
最后当发现当前节点没有子节点时,就根据新节点的值的大小,让新节点成为当前节点的左或右子节点。
如果插入结点的权值是随机的(换言之,是随机插入的),那这个朴素搜索树的高度较小(接近 ,其中 为结点数),而每一层的节点数较多,即它的形状会非常的「胖」。上图的 Treap 就是一个例子。因此此时的任意操作复杂度都将会是 左右。
不过,这只是在随机情况下的复杂度,如果我们按照下面这个非常有序的顺序给一个朴素的搜索树插入节点:
1 2 3 4 5那么这棵树将会退化成链,即变得非常「瘦长」(每次插入的节点都比前面的大,所以都被安排到右子节点了):
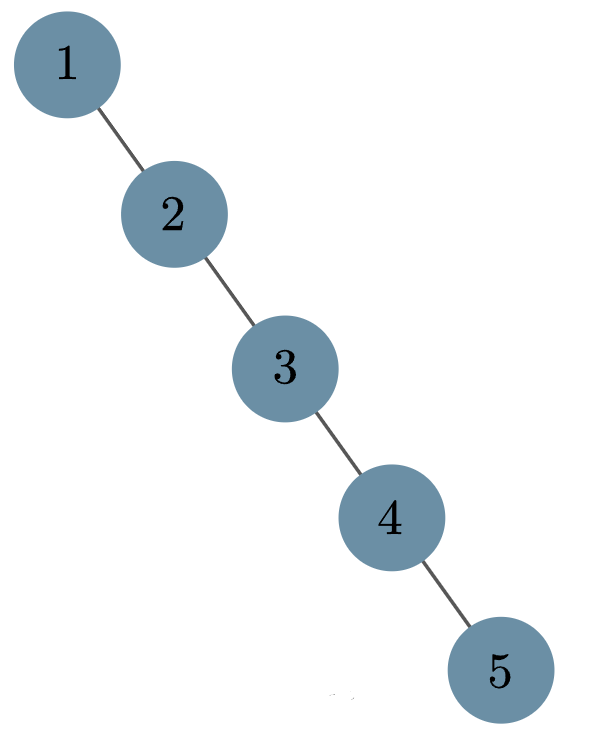
不难看出,查询的复杂度也从 变成了 .
而 treap 为了解决这个问题、达到一个较为「平衡」的状态,通过维护随机的优先级满足堆性质,「打乱」了节点的插入顺序,从而让二叉搜索树达到了理想的复杂度,避免了退化成链的问题。
Treap 复杂度的证明
由于 treap 各种操作的复杂度都和所操作的结点的深度有关,我们首先证明,所有结点的期望高度都是 .
记号约定
为了方便表述,我们约定:
- 是节点个数。
- Treap 结点中满足二叉搜索树性质的称为 权值,满足堆性质的(也就是随机的)称为 优先级。不妨设优先级满足小根堆性质。
- 表示权值第 小的结点。
- 表示集合 ,即按权值升序排列后第 个到第 个的结点构成的集合。
- 表示结点 的深度。规定根节点的深度是 .
- 是一个指示器随机变量,当 是 的祖先时值为 ,否则为 . 特别地,.
- 表示事件 发生的概率。
树高的证明
由于结点 的深度等于它祖先的个数,因此有
那么根据期望的线性性,有
由于 是指示器随机变量,它的期望就等于它为 的概率,因此
我们先证明引理: 当且仅当 的优先级是 中最小的。
引理的证明
证明:考虑分类讨论 和 的情况。
- 若 是根节点:由于优先级满足小根堆性质, 的优先级最小,并且对于任意的 , 都是 的祖先。
- 若 是根节点:同理, 优先级最小,因此 不是 中优先级最小的;同时 也不是 的祖先。
- 若 和 在根节点的两个子树中(一左一右),那么根节点 . 因此 的优先级不可能是 中最小的(因为根节点的比它小)。同时,由于 和 分属两个子树, 也不是 的祖先。
- 若 和 在根节点的同一个子树中,此时可以将这个子树单独拿出来作为一棵新的 treap,递归进行上面的证明即可。
那么根据引理,深度的期望可以转化成
又因为结点的优先级是随机的,我们假定集合 中任何一个结点的优先级最小的概率都相同,那么
因此每个结点的期望高度都是 .
而朴素的二叉搜索树的操作的复杂度均是 ,同时 treap 维护堆性质的复杂度也是 的,因此 treap 各种操作的期望复杂度都是 .
期望复杂度的感性理解
首先,我们需要认识到一个节点的 属性是和它所在的层数有直接关联的。再回忆堆的性质:
- 子节点值()比父节点大或小(取决于是小根堆还是大根堆)
我们发现层数低的节点,比如整个树的根节点,它的 属性也会更小(在小根堆中)。并且,在朴素的搜索树中,先被插入的节点,也更有可能会有比较小的层数。我们可以把这个 属性和被插入的顺序关联起来理解,这样,也就理解了为什么 treap 可以把节点插入的顺序通过 打乱。
给 treap 插入新节点时,需要同时维护树和堆的性质。其中,搜索树的性质可以在插入时维护,而堆性质的维护则有两种处理方法,分别是旋转和分裂、合并。使用这两种方法的 treap 被分别称为 旋转 treap 和 无旋 treap。
旋转 treap
旋转 treap 维护平衡的方式为旋转,和 AVL 树的旋转操作类似,分为 左旋 和 右旋。即在满足二叉搜索树的条件下根据堆的优先级对 treap 进行平衡操作。
旋转 treap 在做普通平衡树题的时候,是所有平衡树中常数较小的。
下面的讲解中的代码用指针实现了旋转 treap,文末附有数组形式的完整实现。
代码中的 rank 代表前面讲的优先级( 属性),该属性满足的是小根堆性质。
节点结构
struct Node {
Node *ch[2]; // 两个子节点的地址
int val, rank;
int rep_cnt; // 当前这个值(val)重复出现的次数
int siz; // 以当前节点为根的子树大小
Node(int val) : val(val), rep_cnt(1), siz(1) {
ch[0] = ch[1] = nullptr;
rank = rand();
// 注意初始化的时候,rank 是随机给出的
}
void upd_siz() {
// 用于旋转和删除过后,重新计算 siz 的值
siz = rep_cnt;
if (ch[0] != nullptr) siz += ch[0]->siz;
if (ch[1] != nullptr) siz += ch[1]->siz;
}
};旋转
旋转操作是 treap 的一个非常重要的操作,主要用来在保持 treap 树性质的同时,调整不同节点的层数,以达到维护堆性质的作用。
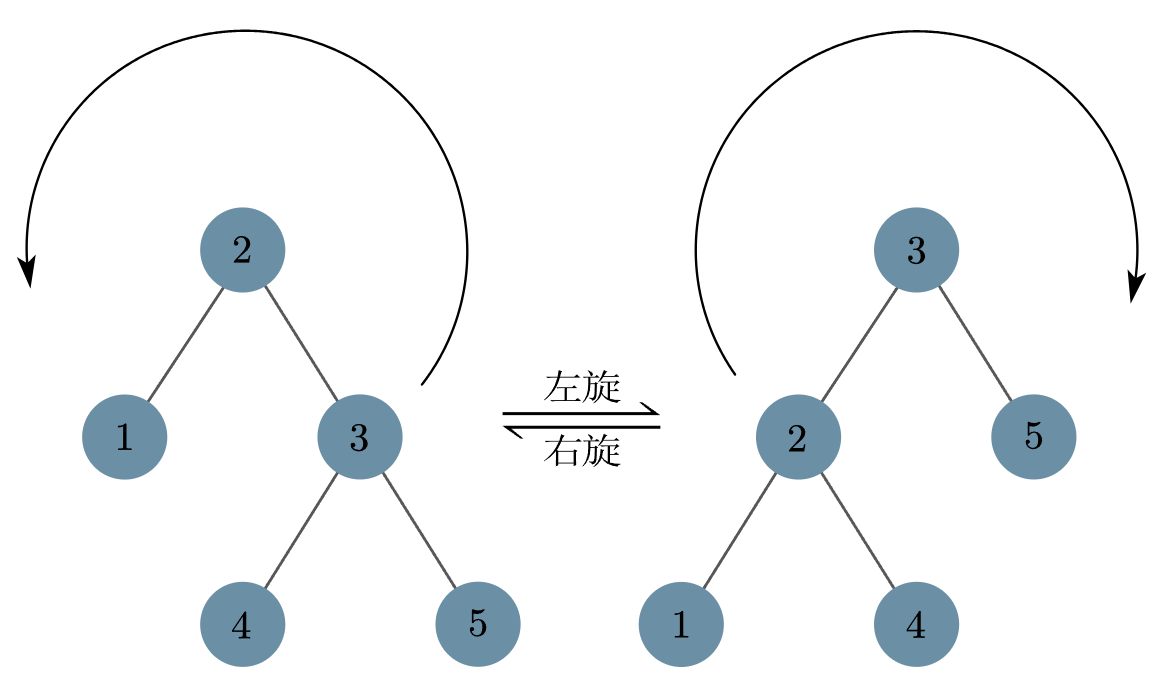
旋转操作的左旋和右旋可能不是特别容易区分,以下是两个较为明显的特点:
旋转操作的含义:
- 在不影响搜索树性质的前提下,把和旋转方向相反的子树变成根节点(如左旋,就是把右子树变成根节点)
- 不影响性质,并且在旋转过后,跟旋转方向相同的子节点变成了原来的根节点(如左旋,旋转完之后的左子节点是旋转前的根节点)
左旋和右旋操作是相互的,如下图。
enum rot_type { LF = 1, RT = 0 };
void _rotate(Node *&cur,
rot_type dir) { // dir 参数代表旋转的方向 0 为右旋,1 为左旋
// 注意传进来的 cur 是指针的引用,也就是改了这个
// cur,变量是跟着一起改的,如果这个 cur 是别的 树的子节点,根据 ch
// 找过来的时候,也是会找到这里的
// 以下的代码解释的均是左旋时的情况
Node *tmp = cur->ch[dir]; // 让 C 变成根节点,
// 这里的 tmp
// 是一个临时的节点指针,指向成为新的根节点的节点
/* 左旋:也就是让右子节点变成根节点
* A C
* / \ / \
* B C ----> A E
* / \ / \
* D E B D
*/
cur->ch[dir] = tmp->ch[!dir]; // 让 A 的右子节点变成 D
tmp->ch[!dir] = cur; // 让 C 的左子节点变成 A
cur->upd_siz(), tmp->upd_siz(); // 更新大小信息
cur = tmp; // 最后把临时储存 C 树的变量赋值到当前根节点上(注意 cur 是引用)
}插入
类似普通二叉搜索树的插入,但是需要在插入的过程中通过旋转来维护优先级的堆性质。
void _insert(Node *&cur, int val) {
if (cur == nullptr) {
// 没这个节点直接新建
cur = new Node(val);
return;
} else if (val == cur->val) {
// 如果有这个值相同的节点,就把重复数量加一
cur->rep_cnt++;
cur->siz++;
} else if (val < cur->val) {
// 维护搜索树性质,val 比当前节点小就插到左边,反之亦然
_insert(cur->ch[0], val);
if (cur->ch[0]->rank < cur->rank) {
// 小根堆中,上面节点的优先级一定更小
// 因为新插的左子节点比父节点小,现在需要让左子节点变成父节点
_rotate(cur, RT); // 注意前面的旋转性质,要把左子节点转上来,需要右旋
}
cur->upd_siz(); // 插入之后大小会变化,需要更新
} else {
_insert(cur->ch[1], val);
if (cur->ch[1]->rank < cur->rank) {
_rotate(cur, LF);
}
cur->upd_siz();
}
}删除
主要就是分类讨论,不同的情况有不同的处理方法,删完了树的大小会有变化,要注意更新。并且如果要删的节点有左子树和右子树,就要考虑删除之后让谁来当父节点(维护 rank 小的节点在上面)。
void _del(Node *&cur, int val) {
if (val > cur->val) {
_del(cur->ch[1], val);
// 值更大就在右子树,反之亦然
cur->upd_siz();
} else if (val < cur->val) {
_del(cur->ch[0], val);
cur->upd_siz();
} else {
if (cur->rep_cnt > 1) {
// 如果要删除的节点是重复的,可以直接把重复值减小
cur->rep_cnt--, cur->siz--;
return;
}
uint8_t state = 0;
state |= (cur->ch[0] != nullptr);
state |= ((cur->ch[1] != nullptr) << 1);
// 00 都无,01 有左无右,10,无左有右,11 都有
Node *tmp = cur;
switch (state) {
case 0:
delete cur;
cur = nullptr;
// 没有任何子节点,就直接把这个节点删了
break;
case 1: // 有左无右
cur = tmp->ch[0];
// 把根变成左儿子,然后把原来的根节删了,注意这里的 tmp 是从 cur
// 复制的,而 cur 是引用
delete tmp;
break;
case 2: // 有右无左
cur = tmp->ch[1];
delete tmp;
break;
case 3:
rot_type dir = cur->ch[0]->rank < cur->ch[1]->rank
? RT
: LF; // dir 是 rank 更小的那个儿子
_rotate(cur, dir); // 这里的旋转可以把优先级更小的儿子转上去,rt 是 0,
// 而 lf 是 1,刚好跟实际的子树下标反过来
_del(
cur->ch[!dir],
val); // 旋转完成后原来的根节点就在旋方向那边,所以需要
// 继续把这个原来的根节点删掉
// 如果说要删的这个节点是在整个树的「上层的」,那我们会一直通过这
// 里的旋转操作,把它转到没有子树了(或者只有一个),再删掉它。
cur->upd_siz();
// 删除会造成大小改变
break;
}
}
}根据值查询排名
操作含义:查询以 cur 为根节点的子树中,val 这个值的大小的排名(该子树中小于 val 的节点的个数 + 1)
int _query_rank(Node *cur, int val) {
int less_siz = cur->ch[0] == nullptr ? 0 : cur->ch[0]->siz;
// 这个树中小于 val 的节点的数量
if (val == cur->val)
// 如果这个节点就是要查的节点
return less_siz + 1;
else if (val < cur->val) {
if (cur->ch[0] != nullptr)
return _query_rank(cur->ch[0], val);
else
return 1; // 如果左子树是空的,说比最小的节点还要小,那这个数字就是最小的
} else {
if (cur->ch[1] != nullptr)
// 如果要查的值比这个节点大,那这个节点的左子树以及这个节点自身肯定都比要查的值小
// 所以要加上这两个值,再加上往右边找的结果
// (以右子树为根的子树中,val 这个值的大小的排名)
return less_siz + cur->rep_cnt + _query_rank(cur->ch[1], val);
else
return cur->siz + 1;
// 没有右子树的话直接整个树 + 1 相当于 less_siz + cur->rep_cnt + 1
}
}根据排名查询值
要根据排名查询值,我们首先要知道如何判断要查的节点在树的哪个部分:
以下是一个判断方法的表:
| 左子树 | 根节点/当前节点 | 右子树 |
|---|---|---|
| 排名 ≤ 左子树的大小 | 排名 > 左子树的大小,并且 ≤ 左子树的大小 + 根节点的重复次数 | 排名 > 左子树的大小 + 根节点的重复次数 |
注意如果在右子树,递归的时候需要对原来的 rank 进行处理。递归的时候就相当去查,在右子树中为这个排名的值,为了把排名转换成基于右子树的,需要把原来的 rank 减去左子树的大小和根节点的重复次数。
可以把所有节点想象成一个排好序的数组,或者数轴(如下),
1 -> |左子树的节点|根节点|右子树的节点| -> n ^ 要查的排名 ⬇转换成基于右子树的排名 1 -> |右子树的节点| -> n ^ 要查的排名
这里的转换方法就是直接把排名减去左子树的大小和根节点的重复数量。
int _query_val(Node *cur, int rank) {
// 查询树中第 rank 大的节点的值
int less_siz = cur->ch[0] == nullptr ? 0 : cur->ch[0]->siz;
// less siz 是左子树的大小
if (rank <= less_siz)
return _query_val(cur->ch[0], rank);
else if (rank <= less_siz + cur->rep_cnt)
return cur->val;
else
return _query_val(cur->ch[1], rank - less_siz - cur->rep_cnt); // 见前文
}查询第一个比 val 小的节点
注意这里使用了一个类中的全局变量,q_prev_tmp。
这个值是只有在 val 比当前节点值大的时候才会被更改的,所以返回这个变量就是返回 val 最后一次比当前节点的值大,之后就是更小了。
int _query_prev(Node *cur, int val) {
if (val <= cur->val) {
// 还是比 val 大,所以往左子树找
if (cur->ch[0] != nullptr) return _query_prev(cur->ch[0], val);
} else {
// 只有能进到这个 else 里,才会更新 q_prev_tmp 的值
q_prev_tmp = cur->val;
// 当前节点已经比 val,小了,但是不确定是否是最大的,所以要到右子树继续找
if (cur->ch[1] != nullptr) _query_prev(cur->ch[1], val);
// 接下来的递归可能不会更改 q_prev_tmp
// 了,那就直接返回这个值,总之返回的就是最后一次进到 这个 else 中的
// cur->val
return q_prev_tmp;
}
return NIL;
}查询第一个比 val 大的节点
跟前一个很相似,只是大于小于号换了一下。
int _query_nex(Node *cur, int val) {
if (val >= cur->val) {
if (cur->ch[1] != nullptr) return _query_nex(cur->ch[1], val);
} else {
q_nex_tmp = cur->val;
if (cur->ch[0] != nullptr) _query_nex(cur->ch[0], val);
return q_nex_tmp;
}
return NIL;
}完整代码
以下为 treap 的模板代码:
#include <iostream>
constexpr int MAXN = 100005;
constexpr int INF = 1 << 30;
int n;
struct treap { // 直接维护成数据结构,可以直接用
int l[MAXN], r[MAXN], val[MAXN], rnd[MAXN], size_[MAXN], w[MAXN];
int sz, ans, rt;
void pushup(int x) { size_[x] = size_[l[x]] + size_[r[x]] + w[x]; }
void lrotate(int &k) {
int t = r[k];
r[k] = l[t];
l[t] = k;
size_[t] = size_[k];
pushup(k);
k = t;
}
void rrotate(int &k) {
int t = l[k];
l[k] = r[t];
r[t] = k;
size_[t] = size_[k];
pushup(k);
k = t;
}
void insert(int &k, int x) { // 插入
if (!k) {
sz++;
k = sz;
size_[k] = 1;
w[k] = 1;
val[k] = x;
rnd[k] = rand();
return;
}
size_[k]++;
if (val[k] == x) {
w[k]++;
} else if (val[k] < x) {
insert(r[k], x);
if (rnd[r[k]] < rnd[k]) lrotate(k);
} else {
insert(l[k], x);
if (rnd[l[k]] < rnd[k]) rrotate(k);
}
}
bool del(int &k, int x) { // 删除节点
if (!k) return false;
if (val[k] == x) {
if (w[k] > 1) {
w[k]--;
size_[k]--;
return true;
}
if (l[k] == 0 || r[k] == 0) {
k = l[k] + r[k];
return true;
} else if (rnd[l[k]] < rnd[r[k]]) {
rrotate(k);
return del(k, x);
} else {
lrotate(k);
return del(k, x);
}
} else if (val[k] < x) {
bool succ = del(r[k], x);
if (succ) size_[k]--;
return succ;
} else {
bool succ = del(l[k], x);
if (succ) size_[k]--;
return succ;
}
}
int queryrank(int k, int x) {
if (!k) return 0;
if (val[k] == x)
return size_[l[k]] + 1;
else if (x > val[k]) {
return size_[l[k]] + w[k] + queryrank(r[k], x);
} else
return queryrank(l[k], x);
}
int querynum(int k, int x) {
if (!k) return 0;
if (x <= size_[l[k]])
return querynum(l[k], x);
else if (x > size_[l[k]] + w[k])
return querynum(r[k], x - size_[l[k]] - w[k]);
else
return val[k];
}
void querypre(int k, int x) {
if (!k) return;
if (val[k] < x)
ans = k, querypre(r[k], x);
else
querypre(l[k], x);
}
void querysub(int k, int x) {
if (!k) return;
if (val[k] > x)
ans = k, querysub(l[k], x);
else
querysub(r[k], x);
}
} T;
using std::cin;
using std::cout;
int main() {
cin.tie(nullptr)->sync_with_stdio(false);
srand(123);
cin >> n;
int opt, x;
for (int i = 1; i <= n; i++) {
cin >> opt >> x;
if (opt == 1)
T.insert(T.rt, x);
else if (opt == 2)
T.del(T.rt, x);
else if (opt == 3) {
cout << T.queryrank(T.rt, x) << '\n';
} else if (opt == 4) {
cout << T.querynum(T.rt, x) << '\n';
} else if (opt == 5) {
T.ans = 0;
T.querypre(T.rt, x);
cout << T.val[T.ans] << '\n';
} else if (opt == 6) {
T.ans = 0;
T.querysub(T.rt, x);
cout << T.val[T.ans] << '\n';
}
}
return 0;
}