迭代加深搜索
定义
迭代加深是一种 每次限制搜索深度的 深度优先搜索。
解释
迭代加深搜索的本质还是深度优先搜索,只不过在搜索的同时带上了一个深度 ,当 达到设定的深度时就返回,一般用于找最优解。如果一次搜索没有找到合法的解,就让设定的深度加一,重新从根开始。
既然是为了找最优解,为什么不用 BFS 呢?我们知道 BFS 的基础是一个队列,队列的空间复杂度很大,当状态比较多或者单个状态比较大时,使用队列的 BFS 就显出了劣势。事实上,迭代加深就类似于用 DFS 方式实现的 BFS,它的空间复杂度相对较小。
当搜索树的分支比较多时,每增加一层的搜索复杂度会出现指数级爆炸式增长,这时前面重复进行的部分所带来的复杂度几乎可以忽略,这也就是为什么迭代加深是可以近似看成 BFS 的。
过程
首先设定一个较小的深度作为全局变量,进行 DFS。每进入一次 DFS,将当前深度加一,当发现 大于设定的深度 就返回。如果在搜索的途中发现了答案就可以回溯,同时在回溯的过程中可以记录路径。如果没有发现答案,就返回到函数入口,增加设定深度,继续搜索。
伪代码
IDDFS(u,d)
if d>limit
return
else
for each edge (u,v)
IDDFS(v,d+1)
return注意事项
在大多数的题目中,广度优先搜索还是比较方便的,而且容易判重。当发现广度优先搜索在空间上不够优秀,而且要找最优解的问题时,就应该考虑迭代加深。
实例
假设一张图,ans1 在很深的地方,ans2 离搜索树的根节点最近,但是需要找到的答案为 ans3。
首先考虑 DFS,一般是一搜搜到底,很有可能找到 ans1。若继续查找,很有可能花费太多时间。时间效率低。
再来考虑 BFS,它可以找到最近的答案 ans2。若继续查找,很有可能存储状态的队列会浪费巨大空间。空间效率低
现在引出 IDDFS,它通常适用于有两个条件的问题:一是它是个最优解问题,二是最优的答案深度最小。且能够快速地找到答案。
假设在搜索树中,每层树都有 3 个方案,即是搜索树为一颗 3 叉树,共 2 层,ans 在 3。
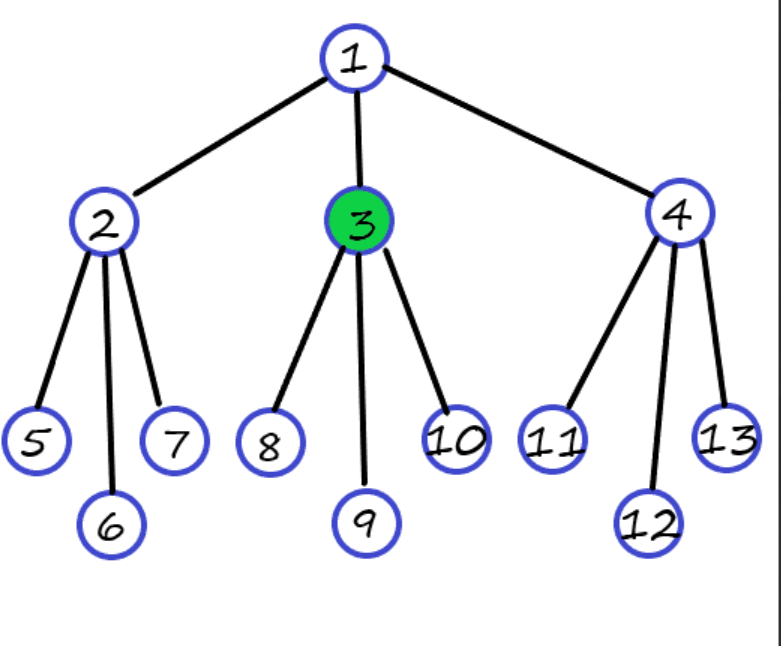
先来对比 DFS,搜索路径为 1−2−5−2−6−2−7−2−1−3,找到答案。有最坏情况,即每一个分支都是一个无底洞,若永远搜索不到答案,就会卡在里面。
再来对比 BFS,搜索路径为 1−2−3,看起来比较短,但是队列中有 1,2,5,6,7,3 的信息,若答案更深一些,那么就会炸空间。
通过上述两个例子,可以知道 DFS 和 BFS 的局限性,但也各有千秋。结合两种算法,就有了迭代加深。首先限定一个层数,对于搜索树进行深度优先搜索。假设这个层数为 1,那么深搜只会搜索到 2,不会继续加深。首先试探性地来找答案,直到找到答案位置。很明显,上面几层的点会搜到很多遍,但时间复杂度对于 DFS 来说比较优,而在空间复杂度上比 BFS 上略胜一筹。
很容易就写出模板:
int max_depth = min_depth;
Id_Dfs( int current_depth , int max_depth ) {
if( current_depth > max_depth ) return ;
if( 找到答案 ){ 输出答案 ; (exit(0) ; || return ;) }
for each ( 当前节点的儿子节点 )
Id_Dfs(current_depth + 1, max_depth) ;
}
for(; ; max_depth++ ) {
Id_Dfs( 0 , i ) ;
}示例题目
一个与 n 有关的整数加成序列 满足以下四个条件:
- 对于每一个 k() 都存在有两个整数 i 和 j(,i 和 j 可以相等 )) ,使得
你的任务是:给定一个整数 n,找出符合上述四个条件的长度最小的整数加成序列。如果有多个满足要求的答案,只需要输出任意一个解即可。
思路
按照 1,2,4,8... 这样来排列,找出最少需要的次数那么最少的层数就找到了,就减少了之前做的无用功。
树上的子节点也较为好找,只需要将之前搜索到的数字,按照题意两两搭配找到下一项。
只需要按照 IDDFS 的规则搜索就行了。但重点在于剪枝,写在注释里。
示例代码
#include <cstdio>
#include <cstring>
bool Quick_Read(int &N) {
N = 0;
int op = 1;
char c = getchar();
while(c < '0' || c > '9') {
if(c == '-')
op = -1;
c = getchar();
}
while(c >= '0' && c <= '9') {
N = (N << 1) + (N << 3) + (c ^ 48);
c = getchar();
}
N *= op;
return N != 0;
}
void Quick_Write(int N) {
if(N < 0) {
putchar('-');
N = -N;
}
if(N >= 10)
Quick_Write(N / 10);
putchar(N % 10 + 48);
}
const int MAXN = 1e5 + 5;
int ans[MAXN];
int limit;
bool flag;
int n;
void Id_Dfs(int nowdepth) {
if(nowdepth > limit || flag)//达到层数不在恋战或找到答案,直接跳出
return;
if(ans[nowdepth] == n) {//满足题意
flag = true;
return;
}
for(int i = nowdepth; i >= 1; i--) {
for(int j = nowdepth; j >= i; j--) {//两两搭配,且答案越大越容易找到解,故而到着找
if(ans[i] + ans[j] <= n && ans[i] + ans[j] > ans[nowdepth]) {//满足题意 1,2 两点的搜索
int now;//找到下一项
ans[nowdepth + 1] = now = ans[i] + ans[j];
for(int k = nowdepth + 2; k <= limit; k++)
//从 nowdepth + 1 这一项开始,后面最大时也就是 now 不停扩大 2 倍,若最大都达不到 n,舍去不求
now <<= 1;
if(now < n)
continue;
Id_Dfs(nowdepth + 1);//搜索下一层
if(flag)//找到答案
return;
}
}
}
}
void Work() {
for(; !flag; limit++)//直到找到答案时停止搜索
Id_Dfs(1);
for(int i = 1; i < limit; i++) {//输出
Quick_Write(ans[i]);
putchar(' ');
}
putchar('\n');
}
void Init() {
limit = 1;
int test = 1;
while(test < n) {//找到最小层数
test <<= 1;
limit++;
}
ans[1] = 1;
flag = false;
}
int main() {
while(Quick_Read(n)) {//多组输入输出,到 0 为止
Init();
Work();
}
return 0;
}